Data Engineering
VOR WELCHEN PROBLEMEN STEHEN UNTERNEHMEN?
Unternehmen nutzen Data Warehouses (DWH) und Data Lakes, um eine große Menge an Informationen zu sammeln und zu speichern. Das Problem tritt auf, wenn Unternehmen versuchen, unstrukturierte und widerspruchsvolle Daten aus verschiedenen Quellen zu kombinieren. Die Daten gehen verloren, werden dupliziert, es kommen auch logische Konflikte vor. Dies führt zu einer geringeren Qualität von Daten und Analyseberichten, die auf ihnen basieren.
WAS IST DATA ENGINEERING?
Data Engineering stellt eine Programmierung der Datenerfassung, -speicherung, -verarbeitung, -suche und -visualisierung dar.
Data Engineering hilft, stabile ETL- und ELT-Prozesse zur Datenerfassung und Datenbereitstellung für Analysesysteme, maschinelle Lernalgorithmen, Data Science zu entwickeln.
| Die qualitativen Daten werden Mitarbeitern des Unternehmens in der richtigen Form zur Verfügung gestellt. |
WELCHE VORTEILE ERHALTEN UNTERNEHMEN?
- Transparenz von Prozessen der Datensammlung von externen und interne Quellen, deren Aufbewahrung, Verarbeitung und Übertragung in Unternehmenssysteme.
- Aktuelle vorbereitete Daten, für Analysesysteme, maschinelle Lernalgorithmen und Data Science.
- Präzise Analysemodelle, zum Beispiel, für Prognose der Kundenabwanderung, des Betrugs, usw.
WELCHE SERVICES BIETEN WIR UNTERNEHMEN AN?
1/ Implementierung von Datenintegrationsmethoden
Wir entwickeln und implementieren Datenextraktions-, Datentransformations- und Datenladeprozesse (ETL- und ELT-Prozesse), Methoden zur Datenqualitätsprüfung und Datenmaskierung (dQM), projektieren Prozesse für verteilte Berechnungen.
2/ Implementierung von Datenanalyse- und Datenvisualisierungssystemen
Wir implementieren Analysesysteme, die aktuelle Daten verarbeiten können: Berichte erfassen und Prognosen stellen. Bei Bedarf stellen wir die präskriptive Analyse ein, um Hypothesen zu prüfen und wahrscheinliche Situationsentwicklungsszenarien zu erhalten.
3/ DWH-, Data Lake-Entwicklung
Wir entwickeln Data Warehouse und Data Lake auf Basis der Lösungen von klassischen Datenbankverwaltungssystemen, Datenbankverwaltungssystem MPP (Multi Parallel Processing) und Big DBMS Data (distributed computing). Lösungen können große Mengen an Informationen und Datenströme online verarbeiten.
4/ Systemmigration in Cloud
Wir migrieren von on-premise in Cloud sowohl innerhalb eines als auch verschiedener Anbieter.
DATA ENGINEERING-EXPERTISE IN CLOUD-SERVICES
Wir stellen bereit und passen die Lösungsinfrastruktur in Cloud an




DATA ENGINEERING IN DER BEDARFSHIERARCHIE FÜRS DATENMANAGEMENT
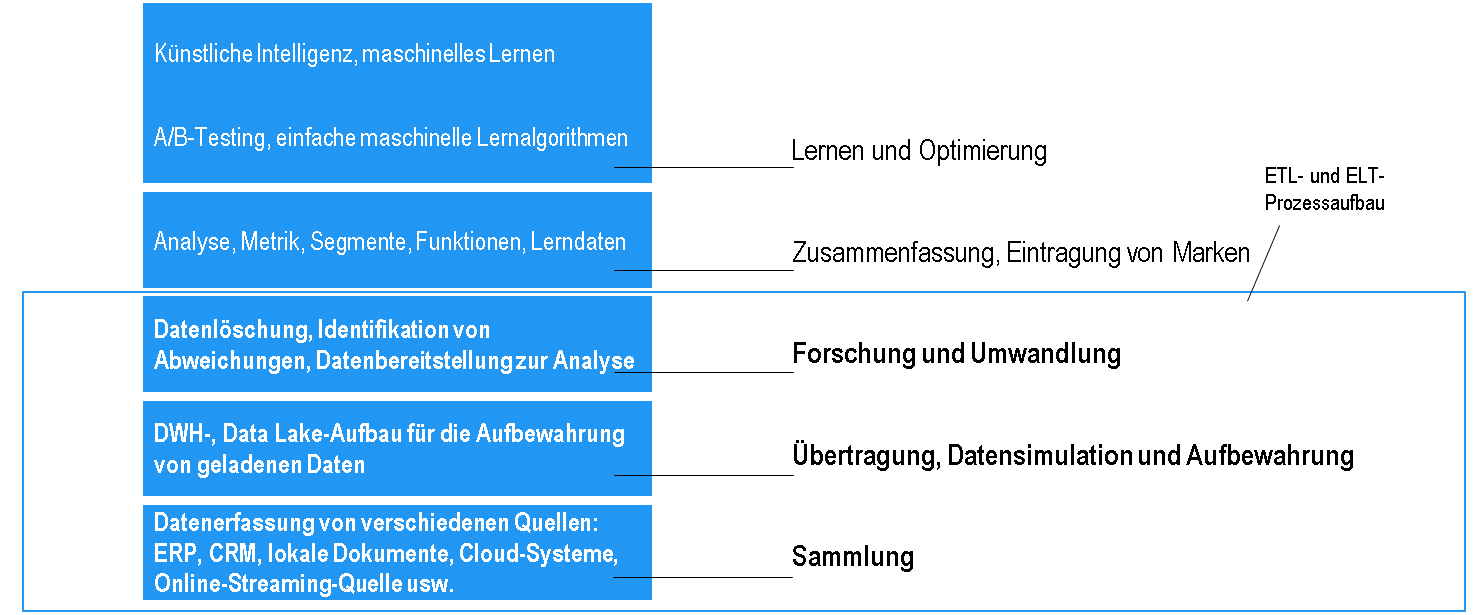
KDIE WICHTIGSTEN UNTERSCHIEDE ZWISCHEN ETL- UND ELT-PROZESSEN
Der ETL-Prozess arbeitet mit Daten, deren Struktur bei der DWH-Simulation vordefiniert wird. Die Datentransformation erfolgt in der Bereitstellungszone, und in Zielsysteme werden verarbeitete Informationen übertragen, die den Standards wie GDPR, HIPAA usw. erfüllt.
Bei ELT-Prozessen werden alle Daten in Data Lake oder Zielsysteme geladen und nur nach dem Laden verarbeitet. Dieser Ansatz bietet mehr Flexibilität an und vereinfacht die Aufbewahrung bei neuen Datenformaten.
ETL-Prozess
Extract
Die Daten werden aus externen und internen Quellen extrahiert: ERP, CRM, lokale Dokumente, Internet, Cloud-Systeme, IoT-Sensoren und andere Online-Streaming-Quellen usw. Danach werden sie zu Transformationen weitergeleitet.
 |
Transform
Die Daten werden gelöscht, gefiltert, gruppiert und aggregiert. Die Rohdaten werden in einen analysebereiten Datensatz umgewandelt. Das Verfahren erfordert eine klare Verständigung von Business-Aufgaben sowie Vorhandensein von fachbezogenen Grundkenntnissen.
|
Load
Die verarbeiteten strukturierten Daten werden in DWH oder Zielsysteme geladen. Der ermittelte Datensatz wird von Endbenutzern verwendet oder ist Eingabefluss zu einem anderen ETL-Prozess.
ELT-Prozess
Extract
Die Daten werden aus externen und internen Quellen extrahiert: ERP, CRM, lokale Dokumente, Internet, Cloud-Systeme, IoT-Sensoren und andere Online-Streaming-Quellen usw.
|
Load
Die Rohdaten werden in Data Lake oder Zielsysteme geladen. Die Daten werden dann transformiert.
|
Transform
Die Daten werden gelöscht, gefiltert, gruppiert und aggregiert. Der ELT-Prozess kann nur einen Teil von Daten verarbeiten, der für eine spezifische Aufgabe erforderlich ist.
Kontaktieren Sie uns
Bitte füllen Sie das Formular aus, um mit uns in Kontakt zu treten und uns alle relevanten Details mitzuteilen. Sie können uns gerne zusätzliche Informationen oder spezifische Fragen zukommen lassen, die Ihnen einfallen könnten.
Unser Team ist bestrebt, schnell und gründlich zu antworten, und wir freuen uns darauf, bald von Ihnen zu hören!